Mathematical reasoning has long been a critical area of research within computer science. With the advancement of large language models (LLMs), there has been significant progress in automating mathematical problem-solving. This involves the development of models that can interpret, solve, and explain complex mathematical problems, making these technologies increasingly relevant in educational and practical applications. LLMs are transforming how we approach mathematical education and research, providing tools that enhance understanding and efficiency.
A major challenge in mathematical reasoning is ensuring that models can handle multi-turn interactions. Traditional benchmarks typically evaluate models based on their ability to solve single-turn questions. Still, real-world scenarios often require sustained reasoning and the ability to follow instructions across multiple interactions. This complexity necessitates advanced capabilities in dialogue understanding and dynamic problem-solving. Ensuring that models can manage these complex tasks is crucial for their application in educational tools, automated tutoring systems, and interactive problem-solving assistants.
Existing frameworks for mathematical reasoning in large language models (LLMs) include benchmarks like GSM8K, MATH, and SVAMP, which evaluate single-turn question answering. Prominent models such as MetaMath, WizardMath, and DeepSeek-Math focus on improving performance through techniques like Chain of Thought (CoT) prompting, synthetic data distillation, and extensive pre-training on math-related corpora. These methods enhance models’ abilities in solving isolated math problems but need to improve in evaluating multi-turn, dialogue-based interactions essential for real-world applications.
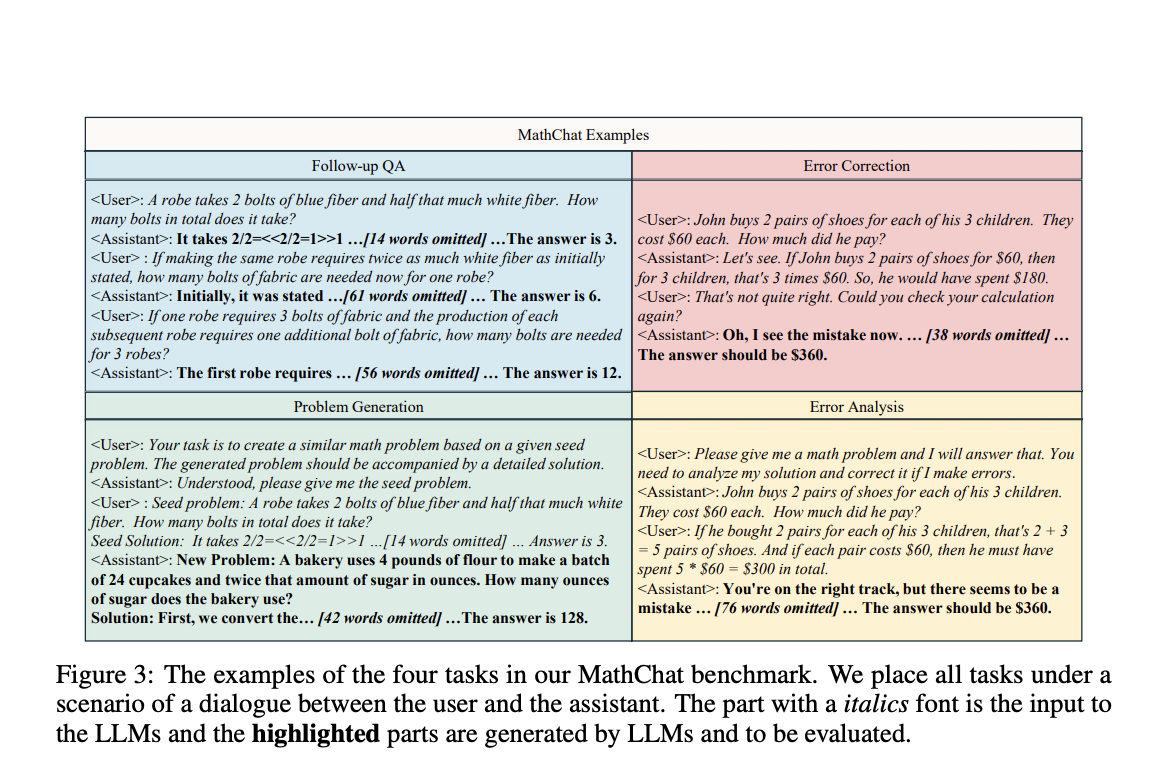
Researchers from the University of Notre Dame team and Tencent AI Lab have introduced a new benchmark named MathChat to address this gap. MathChat evaluates LLMs’ performance in multi-turn interactions and open-ended question-answering. This benchmark aims to push the boundaries of what LLMs can achieve in mathematical reasoning by focusing on dialogue-based tasks. MathChat includes tasks inspired by educational methodologies, such as follow-up questioning and error correction, which are critical for developing models that can understand and respond to dynamic mathematical queries.
The MathChat benchmark includes follow-up question-answering, error correction, analysis, and problem generation. These tasks require models to engage in multi-turn dialogues, identify and correct mistakes, analyze errors, and generate new problems based on given solutions. This comprehensive approach ensures that models are tested on various abilities beyond simple problem-solving. By encompassing multiple aspects of mathematical reasoning, MathChat provides a more accurate assessment of a model’s capabilities in handling real-world mathematical interactions.
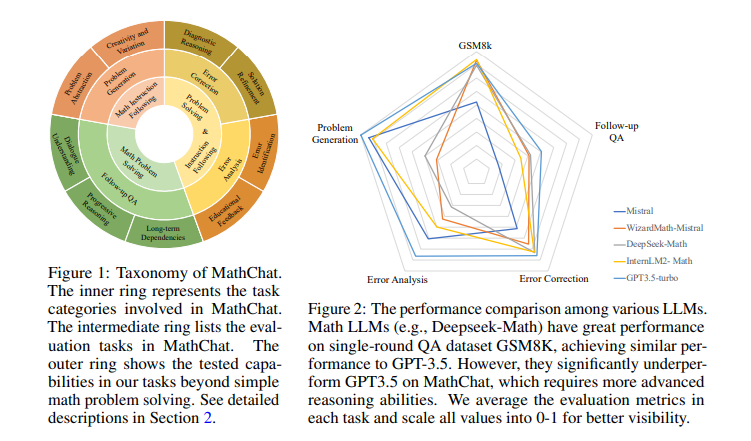
In their experiments, the researchers found that while current state-of-the-art LLMs perform well on single-turn tasks, they struggle significantly with multi-turn and open-ended tasks. For instance, models fine-tuned on extensive single-turn QA data showed limited ability to handle the more complex demands of MathChat. Introducing a synthetic dialogue-based dataset, MathChatsync, significantly improved model performance, highlighting the importance of training with diverse conversational data. This dataset focuses on improving interaction and instruction-following capabilities, essential for multi-turn reasoning.
The researchers evaluated various LLMs on the MathChat benchmark, observing that while these models excel in single-turn question answering, they underperform in scenarios requiring sustained reasoning and dialogue understanding. For example, MetaMath achieved 77.18% accuracy in the first round of follow-up QA but dropped to 32.16% in the second round and 19.31% in the third. Similarly, WizardMath started with 83.20% accuracy, which fell to 44.81% and 36.86% in subsequent rounds. DeepSeek-Math and InternLM2-Math also exhibited significant performance drops in multi-round interactions, with the latter achieving 83.80% accuracy in single-round tasks but much lower in follow-up rounds. The MathChatsync fine-tuning led to substantial improvements: Mistral-MathChat achieved an overall average score of 0.661, compared to 0.623 for Gemma-MathChat, indicating the effectiveness of diverse, dialogue-based training data.
In conclusion, this research identifies a critical gap in current LLM capabilities and proposes a new benchmark and dataset to address this challenge. The MathChat benchmark and MathChatsync dataset represent significant steps in developing models that can effectively engage in multi-turn mathematical reasoning, paving the way for more advanced and interactive AI applications in mathematics. The study highlights the necessity of diverse training data and comprehensive evaluation to enhance the capabilities of LLMs in real-world mathematical problem-solving scenarios. This work underscores the potential for LLMs to transform mathematical education and research by providing more interactive and effective tools.
If you like our work, you will love our newsletter..
Don’t Forget to join our 43k+ ML SubReddit | Also, check out our AI Events Platform







{kind=link}