Numerous groundbreaking models—including ChatGPT, Bard, LLaMa, AlphaFold2, and Dall-E 2—have surfaced in different domains since the Transformer’s inception in Natural Language Processing (NLP). Attempts to solve combinatorial optimization issues like the Traveling Salesman Problem (TSP) using deep learning have progressed logically from convolutional neural networks (CNNs) to recurrent neural networks (RNNs) and finally to transformer-based models. Using the coordinates of N cities (nodes, vertices, tokens), TSP determines the shortest Hamiltonian cycle that passes through each node. The computational complexity grows exponentially with the number of cities, making it a representative NP-hard issue in computer science.
Several heuristics have been used to deal with this. Iterative improvement algorithms and stochastic algorithms are the two main categories under which heuristic algorithms fall. There has been a lot of effort, but it still can’t compare to the best heuristic algorithms. The performance of the Transformer is crucial as it is the engine that solves pipeline problems; however, this is analogous to AlphaGo, which was not powerful enough on its own but beat the top professionals in the world by combining post-processing search techniques like Monte Carlo Tree Search (MCTS). Choosing the next city to visit, depending on the ones already visited, is at the heart of TSP, and the Transformer, a model that attempts to discover relationships between nodes using attention mechanisms, is a good fit for this task. Due to its original design for language models, the Transformer has presented metaphorical challenges in previous studies when applied to the TSP domain.
Among the many distinctions between the language domain transformer and the TSP domain transformer is the significance of tokens. Words and their subwords are considered tokens in the realm of languages. On the other hand, in the TSP domain, every node usually turns into a token. Unlike a collection of words, the set of nodes’ real-number coordinates is infinite, unpredictable, and unconnected. Token indices and the spatial link between neighboring tokens are useless in this arrangement. Duplication is another important distinction. Regarding TSP solutions, unlike linguistic domains, a Hamiltonian cycle cannot be formed by decoding the same city more than once. During TSP decoding, a visited mask is utilized to avoid repetition.
Researchers from Seoul National University present CycleFormer, a TSP solution based on transformers. In this model, the researchers merge the best features of a supervised learning (SL) language model-based Transformer with those of a TSP. Current transformer-based TSP solvers are limited since they are trained with RL. This prevents them from fully utilizing SL’s advantages, such as faster training thanks to the visited mask and more stable convergence. The NP-hardness of the TSP makes it impossible for optimal SL solvers to know the global optimum as problem sizes get too big. However, this limitation can be circumvented if a transformer trained on reasonable-sized problems is generalizable and scalable. Consequently, for the time being, SL and RL will coexist.
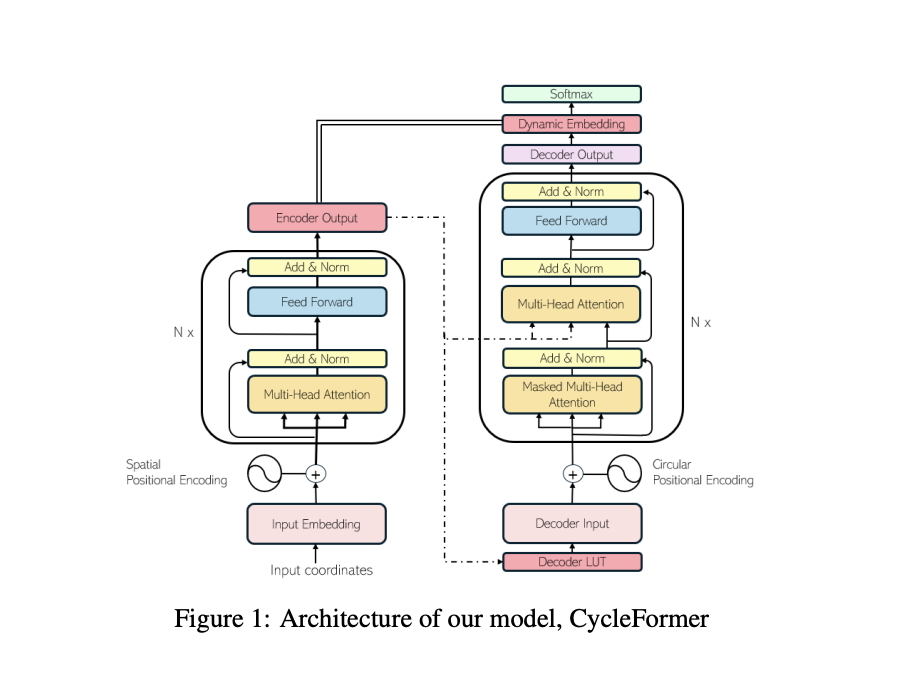
The team’s exclusive emphasis is on the symmetric TSP, defined by the distance between any two points and is constant in all directions. They substantially changed the original design to guarantee that the Transformer embodies the TSP’s properties. Because the TSP solution is cyclical, they ensured that their decoder-side positional encoding (PE) would be insensitive to rotation and flip. Thus, the starting node is very related to the nodes at the beginning and end of the tour but very unrelated to the nodes in the middle.
The researchers use the encoder’s 2D coordinates for spatial positional encoding. The positional embeddings used by the encoder and decoder are completely different. The context embedding (memory) from the encoder’s output serves as the input to the decoder. To quickly maximize the use of acquired information, this strategy takes advantage of the fact that the set of tokens used in the encoder and the decoder is the same in TSP. They swap out the last linear layer of the Transformer with a Dynamic Embedding; this is the graph’s context encoding and acts as the encoder’s output (memory).
The usage of positional embedding and token embedding, as well as the change of the decoder input and exploitation of the encoder’s context vector in the decoder output, are two ways in which CycleFormer differs dramatically from the original Transformer. These enhancements demonstrate the potential for transformer-based TSP solvers to improve by adopting performance improvement strategies employed in Large Language Models (LLMs), such as raising the embedding dimension and the number of attention blocks. This highlights the ongoing challenges and the exciting possibilities for future advancements in this field.
According to extensive experimental results, with these design characteristics, CycleFormer can outperform SOTA models based on transformers while keeping the shape of the Transformer in TSP-50, TSP-100, and TSP-500. The ‘optimality gap ‘, a term used to measure the difference between the best possible solution and the solution found by the model, between SOTA and TSP-500 during multi-start decoding is 3.09% to 1.10%, a 2.8-fold improvement, thanks to CycleFormer.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 43k+ ML SubReddit | Also, check out our AI Events Platform







{kind=link}